Como se Tornar um Engenheiro de Dados: Um Cronograma de Estudos, Guia Didático, Direto e Sem Enrolação - Um norte


Se você está começando do zero ou pensando em migrar para a área de Engenharia de Dados, provavelmente já se perguntou: por onde eu começo? O que de fato é essencial? Quantas horas preciso estudar para conseguir meu primeiro emprego?
Neste artigo, você vai encontrar um guia prático sem enrolação e com uma estrutura clara. Bora lá!?
O que faz um Engenheiro de Dados?
Engenheiros de Dados são os responsáveis por construir os "encanamentos" que transportam, limpam e organizam dados para que analistas e cientistas possam extrair valor deles. Isso envolve desde a ingestão de dados de diferentes fontes, até o armazenamento e a disponibilização eficiente para consumo.
Em resumo: é a pessoa que garante que os dados certos, limpos e atualizados, estejam no lugar certo, na hora certa.
Quais Tecnologias Estudar? E em Que Ordem?
Uma das maiores dúvidas de quem está começando é: o que estudar? A resposta curta: não tente aprender tudo ao mesmo tempo. Existe uma ordem natural e lógica, e ela importa.
1. Conhecimentos Teóricos(comece por aqui)
| Tema | Descrição rápida | Carga sugerida |
|---|---|---|
| Modelagem de Dados | Entidade-relacionamento (ER), cardinalidade, normalização, modelo dimanesional | 20h |
| Bancos Relacionais (SQL) | Conceitos de tabelas, chaves primárias/estrangeiras, integridade referencial | 10h |
| Bancos NoSQL | Modelos chave-valor, documentos, colunar, grafos. Diferença vs SQL | 10h |
| Armazenamento em Cloud | Conceitos de bucket, partição, data lake, data warehouse, object storage | 10h |
| ETL e ELT | Diferença entre os dois, estágios de extração, transformação e carga | 10h |
| Tipos de Dados + Schema | Tipos primitivos, schema evolutivo, schema-on-read vs schema-on-write | 5h |
| Data Warehouse (DW) | Star schema, snowflake, dimensão fato, OLAP vs OLTP | 10h |
| Conceitos de Pipeline | O que é orquestração, DAGs, dependências, batch vs streaming | 5h |
2. Tecnologias Fundamentais
Essas são as ferramentas que você precisa dominar para entrar na área:
| Tecnologia | Descrição | Carga sugerida |
|---|---|---|
| SQL | absolutamente essencial | 80h |
| Python (com Pandas e NumPy) | linguagem mais usada na área | 100h |
| Cloud (AWS de preferência) | serviços como S3, Lambda, Athena e Glue | 120h |
3. Tecnologias de Alta Prioridade (quando já estiver mais confortável)
| Tecnologia | Descrição | Carga sugerida |
| Spark (PySpark) | processamento de grandes volumes de dados | 150h |
| Airflow | orquestração de pipelines | 80h |
| dbt | transformação de dados analítica e testável | 60h |
| BigQuery | armazém de dados moderno (pode ser outro DW) | 40h |
4. Tecnologias de Média Prioridade
| Tecnologia | Descrição | Carga sugerida |
|---|---|---|
| Kafka | Processamento de eventos e filas distribuídas | 120h |
| Databricks | Plataforma de engenharia e ciência de dados | 120h |
| Cloud Azure | Alternativa à AWS em empresas Microsoft | 100h |
| DW Snowflake | Armazém de dados em nuvem com arquitetura única | 40h |
5. Tecnologias de Baixa Prioridade (nicho menor no mercado brasileiro)
| Tecnologia | Descrição | Carga sugerida |
|---|---|---|
| DW Redshift | Data warehouse da AWS, menos comum no Brasil | 40h |
| Cloud GCP | Nuvem do Google, menos adotada localmente | 80h |
| Terraform (IaC) | Automação de infraestrutura em nuvem | 30h |
| Iceberg | Tabelas versionadas para data lakehouse | 80h |
6. Tecnologias Fundamentais Adicionais
Algumas dessas tecnologias você provavelmente vai aprender de forma natural enquanto estuda as ferramentas principais (como Python, Cloud, Airflow, dbt...).
Ainda assim, vale a pena dedicar um tempo exclusivo para elas, porque são altamente demandadas pelo mercado e fazem parte do dia a dia de qualquer engenheiro de dados em ambientes profissionais.
| Tecnologia | Descrição | Carga sugerida |
| Git e GitHub | versionamento de código | 20h |
| Docker | empacotamento e isolamento de ambientes | 25h |
| CI/CD | deploy automatizado de pipelines | 25h |
| NoSQL | MongoDB ou DynamoDB (fundamentos) | 30h |
7. Tecnologias Complementares (avançado)
Se você chegou até aqui, parabéns — você já está muito à frente da maioria. Essas tecnologias são consideradas mais avançadas, específicas ou utilizadas em nichos do mercado de dados. Nem todo engenheiro de dados precisa dominá-las, mas conhecer algumas pode ser um grande diferencial em empresas mais maduras tecnicamente.
| Tecnologia | Descrição | Carga sugerida |
| Kubernetes | gerenciamento e orquestração de containers | 35h |
| Prometheus e Grafana | monitoramento de métricas e dashboards | 25h |
| Elastic Stack (ELK) | centralização, busca e visualização de logs | 35h |
| Apache Flink | processamento de dados em tempo real | 30h |
| Data Governance | catalogação e rastreamento de dados | 20h |
Além dessas, existem muitas outras ferramentas utilizadas em pipelines, orquestração e integração de dados, como:
- Pentaho Data Integration (PDI) – plataforma de ETL open source ainda usada em muitas empresas legadas
- Apache Hop é o sucessor direto do Pentaho Data Integration (PDI)
- Apache NiFi – automação de fluxo de dados com interface visual
- Talend – solução comercial de integração de dados
- StreamSets, SSIS (SQL Server Integration Services), Luigi, Prefect, entre outras.
Não se preocupe em aprender todas — o mundo dos dados é vasto, e você vai adicionando essas ferramentas conforme os projetos pedirem.
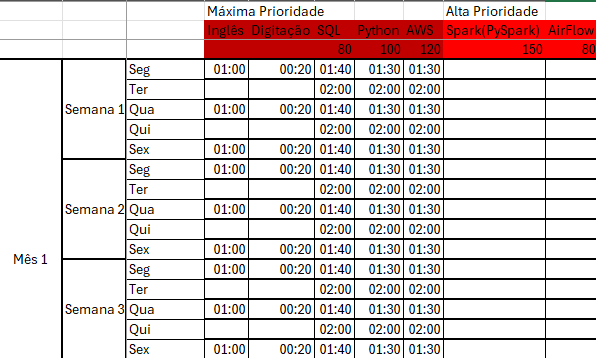
😱 1420 horas de estudo?! Calma, respira…
Fique tranquilo! Ver esse número pode assustar, mas a verdade é que muitas dessas horas se sobrepõem.
Por exemplo: eu sugeri 100h de Python — mas quando você estiver estudando Spark, Airflow ou até dbt, você vai estar automaticamente praticando Python também. Ou seja, você vai estar reforçando sem nem perceber.
Esse cronograma é extenso, eu sei. Estou passando por ele também, e posso te dizer com tranquilidade: ele tem me guiado com clareza, numa sequência lógica que está me fazendo aprender com profundidade e muito mais confiança.
E o melhor: você não precisa cumprir tudo isso para conseguir sua primeira vaga.
Se você cumprir cerca de 70% do passo 1 e 2 (fundamentos e alta prioridade) e 50% do passo 3, com ênfase especial em Spark, é bem provável que já esteja apto a uma vaga de júnior.
O objetivo aqui não é te afogar em conteúdo, mas te mostrar o caminho — e o caminho é possível. Com consistência, você chega lá.
Quantas Horas Preciso Estudar?
Não existe fórmula mágica, mas sim uma estimativa prática com base em carga horária efetiva e aplicada.
| Perfil de estudo | Estimativa de horas totais | Nível esperado |
|---|---|---|
| 📘 Básico | 200h–300h | Compreensão inicial |
| ⚙️ Intermediário | 400h–600h | Pronto para vaga júnior |
| 🚀 Forte | 700h–1000h+ | Forte candidato júnior com chances reais |
Dica: com 500h de estudo bem direcionado e 2 bons projetos no GitHub, você já tem ótimas chances no mercado.
Quantas Horas Estudar por Semana?
| Horas por semana | Conclusão em... |
|---|---|
| 10h/semana | ~142 semanas (~2 anos e 9 meses) |
| 15h/semana | ~95 semanas (~1 ano e 10 meses) |
| 20h/semana | ~71 semanas (~1 ano e 4 meses) |
| 25h/semana | ~57 semanas (~1 ano e 1 mês) |
| 30h/semana | ~47 semanas (~11 meses) |
| 40h/semana | ~36 semanas (~8 a 9 meses) |
Qualidade > Quantidade. Melhor estudar 2h bem focadas do que 6h arrastadas.
Preciso Ter um Portfólio?
Sim! Estudo sem prática vira teoria esquecida. Monte projetos com:
- Pipelines usando Airflow ou dbt
- Banco de dados relacional + NoSQL
- Cloud (AWS ou GCP)
- Extração de dados reais (API, web scraping, CSVs públicos)
Organize tudo no GitHub com README explicando o que você fez, por quê, e o que aprendeu.
📌 Não se trata só de horas… mas do que você aprende nelas.
A quantidade de horas que você estuda não garante um emprego — o que garante é:
- Conhecimento prático e aplicável
- Portfólio - 2 ou 3 projetos reais (pipelines, dashboards, cloud, banco) no GitHub com README bem feito
- Domínio dos fundamentos mais pedidos
- Conseguir demonstrar isso em entrevistas técnicas
Ferramentas para se Organizar
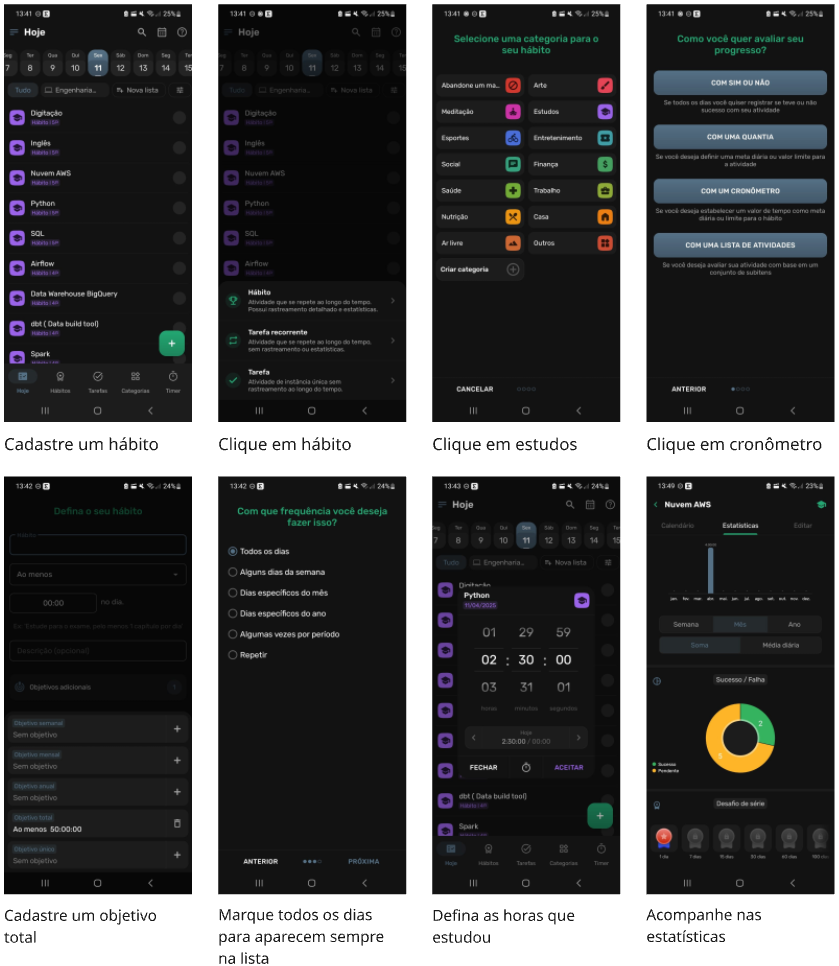
- Gosto muito do HabitNow (Google Play)
- Notion – Utilizo muito para anotações
- Trello ou Kanban – para acompanhar o que está feito e o que vem a seguir
- Excel – se você curte o bom e velho planilhão (eu curto!)
Conclusão
O conteúdo é extenso e pode levar de 1 a 3 anos para ser concluído — vai depender do seu tempo disponível e do esforço que você está disposto a investir.
Este guia abrange desde o nível júnior até o sênior: o júnior vai conhecer e aplicar as ferramentas; o sênior vai dominá-las, entender os porquês por trás das escolhas técnicas e resolver problemas de forma autônoma.
Dizem que você só se torna especialista depois de 10.000 horas de prática. E essas horas, meu amigo, você só conquista trabalhando, errando, melhorando e fazendo de novo.
Este cronograma é o ponto de partida — o resto, você constrói no campo de batalha.
Entrar na Engenharia de Dados não exige ser um gênio. Exige consistência, prática e direcionamento.
Aprenda o que realmente importa, monte projetos que mostrem isso, mantenha constância e se exponha no LinkedIn com conteúdo sobre sua jornada. Não é sobre decorar tudo, é sobre saber resolver problemas com as ferramentas certas.
Eu também estou nessa jornada, e sei como é olhar para essas 1420 horas e pensar: “Será que eu dou conta?”. Acredito de verdade que ter um norte — um roadmap, um cronograma — nos ajuda a não perder foco com caminhos que desviam do nosso objetivo.
Acredite: passo a passo, isso vira carreira.
Boa jornada, engenheiro de dados em construção! Vamos para cima!
Se esse conteúdo foi útil para você, ou se faltou alguma tecnologia ou conhecimento, deixe um comentário com suas opiniões ou sugestões. Caso queira, inscreva-se para receber mais conteúdo sobre engenharia de dados e tecnologia em geral.